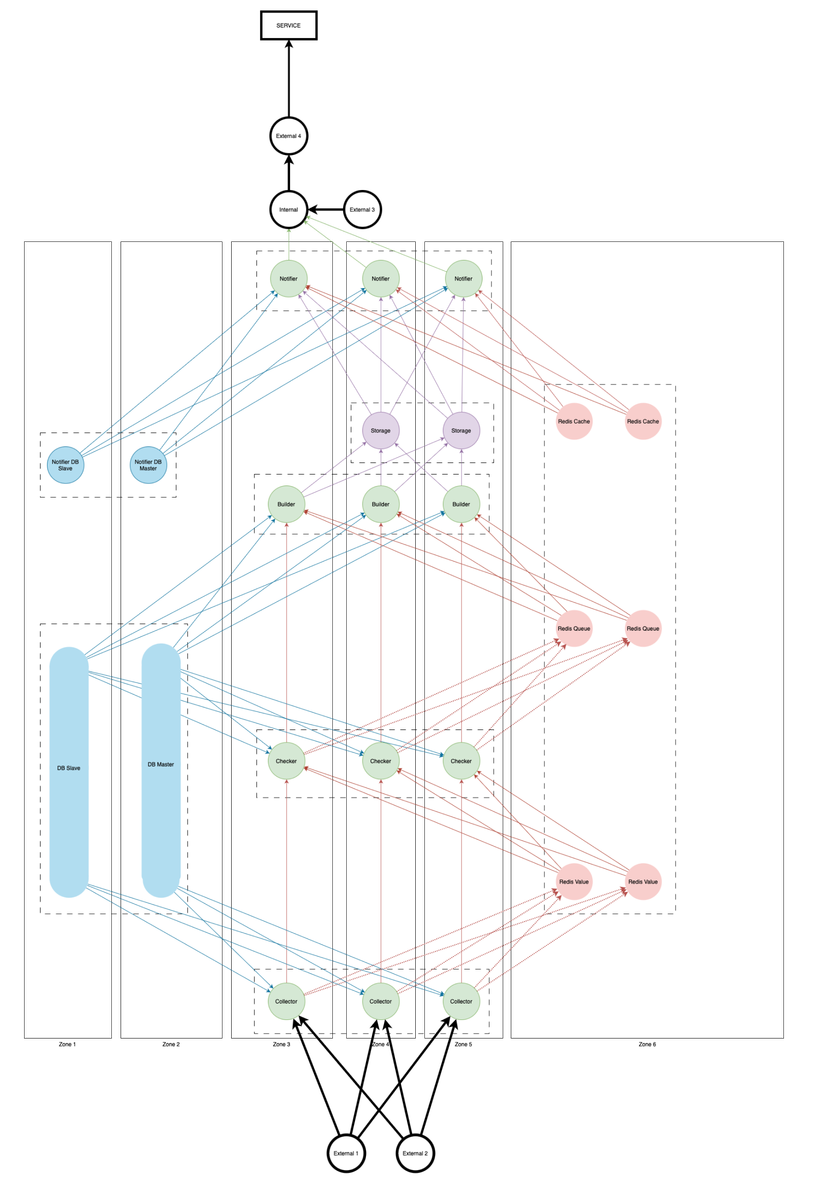
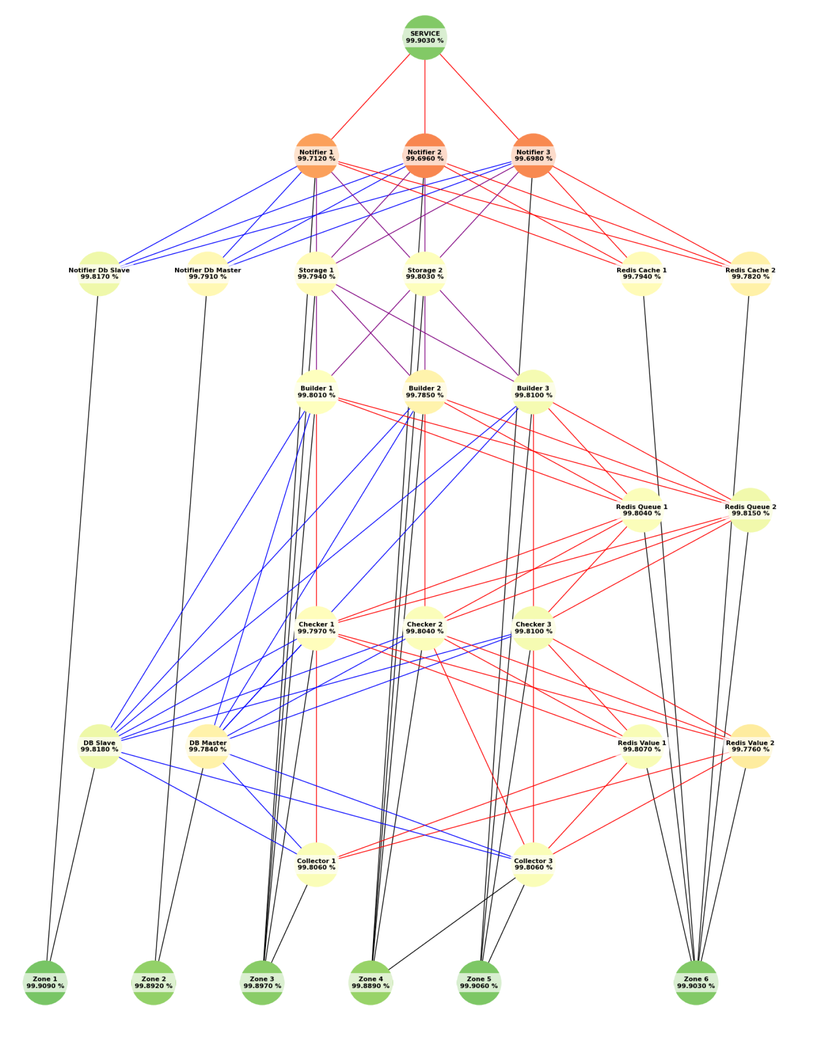
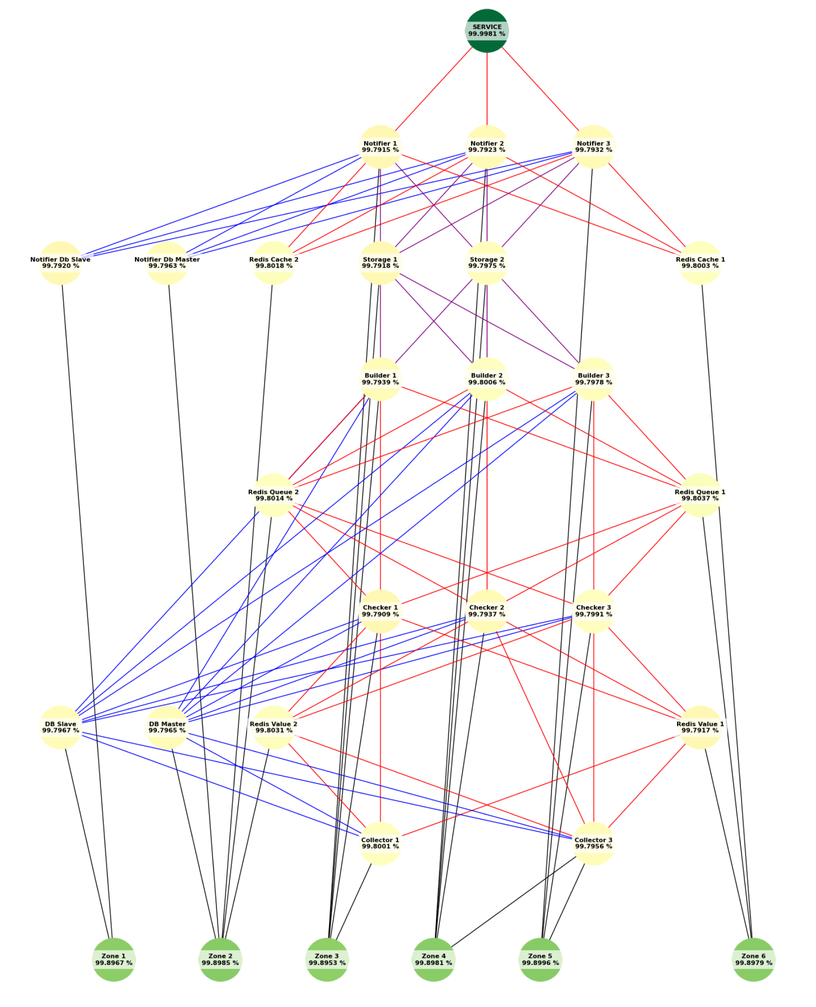
В инфраструктуре Т-Банка сервисы и микросервисы периодически ломаются, поэтому важная задача — своевременно их чинить. Для этого необходимо быстро находить поломки.
Существует несколько подходов к обнаружению сбоев: например, мониторинг внутренней логики, трафика и загруженности ресурсов. Мы в этом проекте работали методами мониторинга трафика.
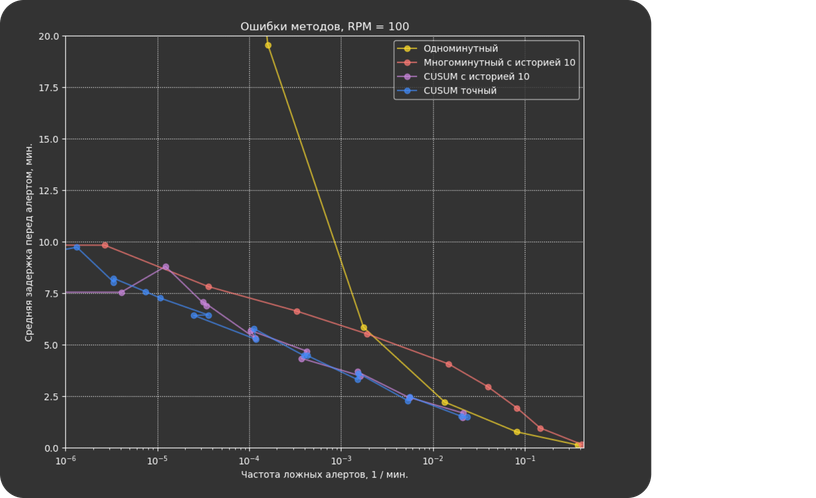
Стандартный способ мониторинга трафика — каждую минуту смотреть на количество запросов, которые завершились с ошибкой, и сравнивать его с порогом p (обычно p = 1% от общего числа запросов). Этот способ хорошо работает в нормальных условиях, но при низкой нагрузке на сервисы он приводит к частым ложным срабатываниям.
Перед нами стояла задача разработать метод, который позволил бы снизить число ошибок и уменьшить нагрузку на SRE.
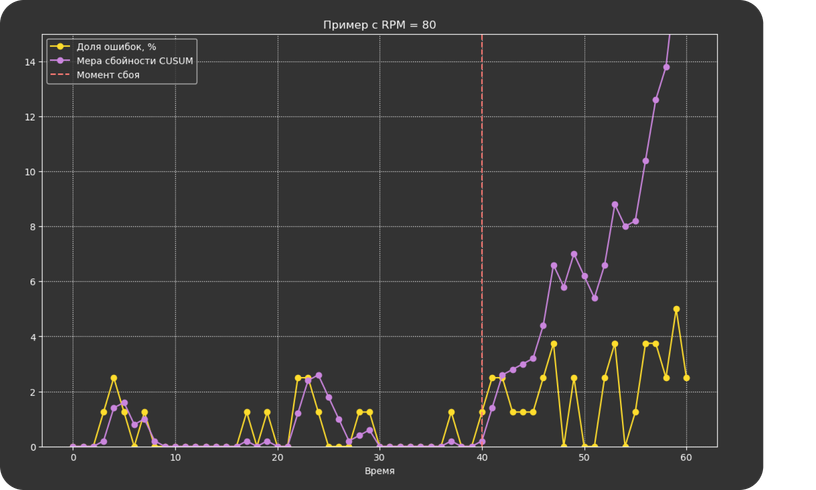
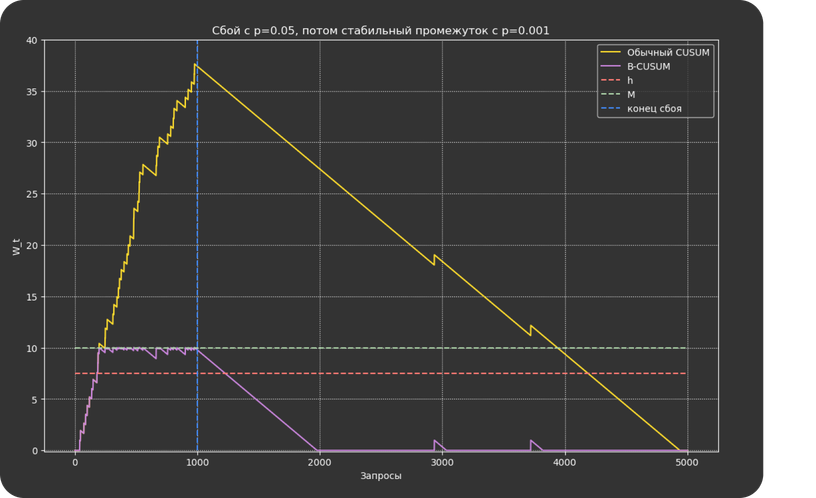
Стандартным методом для решения задач на практике считается алгоритм CUSUM: для принятия решения о сигнале он использует данные за последнюю минуту, а также историю. Для этого он поддерживает меру сбойности сервиса, которая увеличивается с каждым ошибочным запросом и уменьшается с каждым нормальным.
Более формально: если в минуту t пришло Nₜ запросов, из которых Xₜ завершилось с ошибкой, то мера сбойности будет равна Wₜ = max (0, Wt-1 + Xt – pNt)
Если мера сбойности превысила некоторый порог h, метод выдает сигнал об ошибке.