Мотивация: распределенная обработка графов
Алгоритмы партиционирования графов
Иногда графовые данные достигают таких больших объемов, что граф перестает помещаться в оперативную память одной машины. Возникает потребность в распределенной обработке на вычислительных кластерах, которые состоят из нескольких узлов. Расскажем, как организовать распределенное вычисление графовых алгоритмов.
Классический подход —
На реальных графах
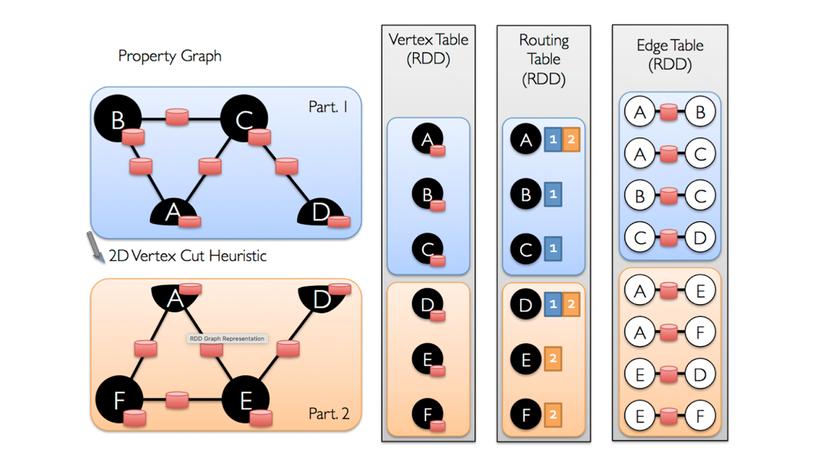
Так граф хранится в GraphX
Задача: реберное разбиение графов
На работу фреймворков вроде Spark сильно влияет стратегия распределения ребер по вычислительным узлам.
Формализуем задачу: дан граф G=(V, E) и число n (количество вычислительных узлов). Мы хотим разбить множества ребер графа на n частей (партиций). Если нужна более наглядная интерпретация, мы хотим раскрасить ребра графа в n цветов. В этой статье мы будем отождествлять цвета и партиции, а еще — использовать слова «разбиение» и «раскраска» как синонимы.
Скажем, разбиение — это функция 𝑓:E → [n] из множества ребер в множество цветов. Наша задача — найти разбиение, которое минимизирует две метрики.
- Первая метрика — дисбаланс. Он равен отношению размера самой большой партиции и среднего размера партиции:
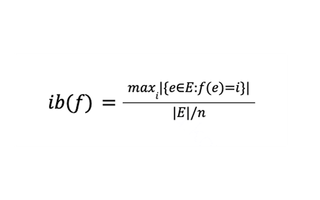
Дисбаланс описывает, насколько равномерно данные, а значит и вычислительная нагрузка, распределятся по узлам кластера. Важно минимизировать его, чтобы избежать ситуации, в которой одни вычислительные узлы долго простаивают в ожидании других узлов.
- Вторая метрика — фактор репликации вершины. Он равен количеству разноцветных ребер, инцидентных ей. Обычно мы хотим минимизировать средний фактор репликации всех вершин:
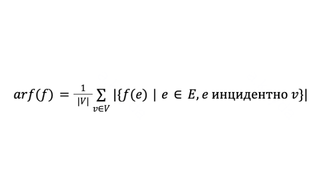
Средний фактор репликации отражает, как много копий у вершин нам пришлось хранить. Еще он показывает объем коммуникаций при вычислениях, потому что обычно во время работы алгоритмов вершина сообщает об изменениях себя всем своим копиям.
Таким образом мы получили задачу о реберном разбиении графов. Эта задача
Сформулируем другие требования к алгоритмам:
- Интересны очень быстрые алгоритмы поиска разбиения, и ради скорости мы готовы пожертвовать точностью решения. Это связано с тем, что разбиение нужно для ускорения обработки графов, поэтому долго считать разбиение бессмысленно.
- Дисбаланс считается более важной метрикой, потому что влияет и на требуемую оперативную память узлов, и на все время работы алгоритма. Поэтому обычно ищут алгоритмы с дисбалансом, близким к 1, и при этом как можно меньшим фактором репликации.
- Самый интересный случай — это когда количество узлов n намного меньше, чем размер графа. Мы ищем алгоритмы, которые хорошо работают именно в этом случае.
Как решали задачу
Мы будем говорить о классе стриминговых алгоритмов без состояния. Это алгоритмы, которые для каждого ребра e=(v, u) определяют его цвет, не используя никакой информации о других ребрах — обычно для этого так или иначе используются хэши номеров вершин. Такие алгоритмы позволяют разбить граф в процессе считывания с диска, то есть с очень маленькими дополнительными издержками. Может показаться, что они не позволяют получить ничего сильно лучше случайного разбиения, но это не так. Мы опишем подход, который позволяет строить алгоритмы в таком классе с хорошими гарантиями на фактор репликации всех вершин.
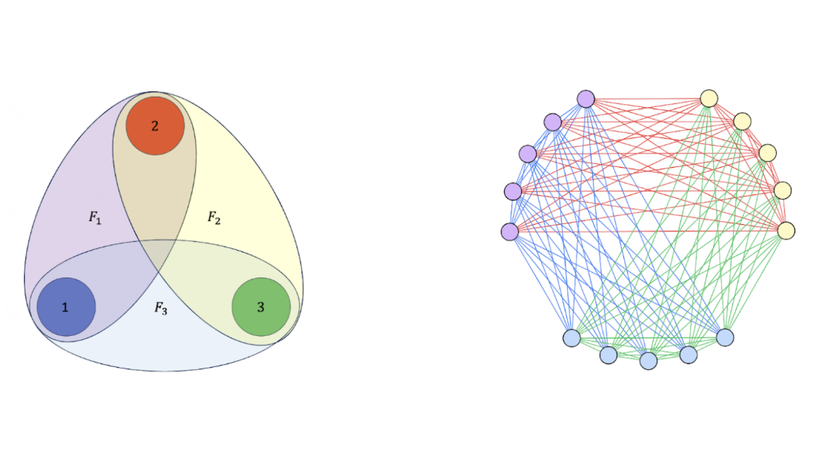
Пример разбиения полного графа на 3 части с дисбалансом 1 и фактором репликации 2. Слева — семейство множеств на 3 элементах, справа — раскраска полного графа, полученная с его помощью. У нее идеальный баланс
В подходе, который мы описываем, для разбиения графа на n цветов нам нужна система множеств F, каждый элемент которой является некоторым множеством цветов.
Алгоритмы устроены следующим образом:
- Каждой вершине v сопоставляется некоторое множество Fv∈F. Оно называется множеством допустимых цветов вершины v. Можно считать, что множества выбираются случайно и независимо. На практике их обычно выбирают по хэшу вершины.
- Каждое ребро раскрашивается в цвет, который допустим для обеих ее вершин. Иными словами, мы берем цвет ребра e=(v, u) как элемент пересечения Fv⋂Fu.
Такие алгоритмы дают подходящее разбиение, если использовать хорошие семейства F. Определим, какие семейства F являются хорошими:
- Для корректной работы алгоритма нужно, чтобы любые два множества из F имели непустое пересечение. В таком случае мы говорим, что F — пересекающееся семейство.
- Фактор репликации вершины v не должен быть больше, чем размер его множества Fv. Поэтому мы хотим минимизировать средний размер множеств в F, который называется рангом системы F.
- Чтобы разбиение получилось сбалансированным, нужно наложить дополнительное условие на семейство F. Ранее известные алгоритмы партиционирования использовали симметричные семейства. Неформально говоря, это семейства множеств, которые выглядят одинаково с точки зрения всех цветов. Формально же семейство симметричное, если для любых двух элементов p, q∈[n] существует φ: [n]→[n], изоморфизм семейства F такой, что φ(p)=q. При использовании симметричных семейств любое ребро имеет одинаковую вероятность раскраски в каждый цвет. В результате при достаточно большом числе ребер симметричные семейства дают почти сбалансированные разбиения с очень большой вероятностью.
Итак, мы связали задачу партиционирования ребер со следующей комбинаторной задачей: по числу n построить симметричное пересекающееся семейство множеств на n элементах с как можно меньшим рангом.
Вот что известно про симметричные пересекающиеся семейства:
- В любом симметричном пересекающемся семействе ранг не меньше чем √n.
- В известных реализованных алгоритмах партиционирования ранг семейства и, как следствие, фактор репликации сильно зависят от числа партиций n. Например, существует алгоритм, который дает фактор репликации не больше ⌈√n⌉ для случая n=q²+q+1, где q — степень простого числа.
- Наилучший результат для произвольного n — семейства с рангом не больше ⌈√1.16n⌉.
- Вопрос о том, всегда ли существует семейство с рангом √n (1+o (1)), — открытый в экстремальной комбинаторике. Его сложность заключается в том, что большинство известных эффективных конструкций таких семейств в значительной степени опираются на то, в каком виде можно представить число n. При этом делать переход от «хороших» n к «плохим» очень сложно
из-за условия симметричности.
Наш метод: сбалансированные системы множеств
Мы обнаружили, что требование к симметричности семейств избыточное. Грубо говоря, мы придумали, как можно ослабить условие симметричности и за счет этого получить алгоритм партиционирования с лучшими гарантиями, чем были известны до этого.
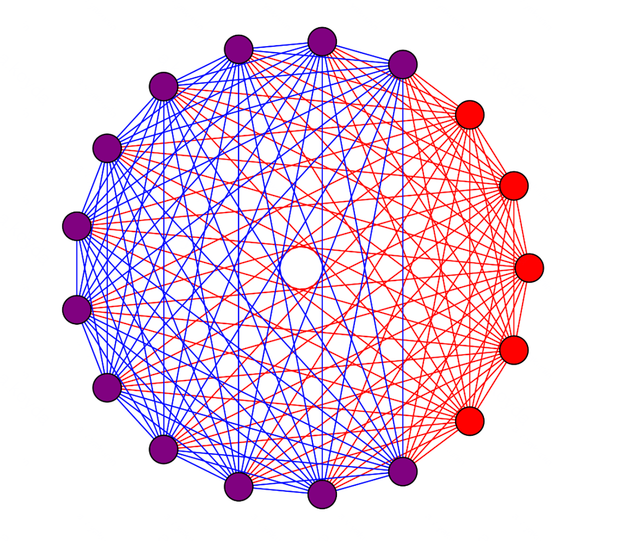
Раскраска полного графа в два цвета, построенная на основе сбалансированных пересекающихся систем. Фактор репликации — примерно 1+ 1/√2
Мы расширяем класс алгоритмов партиционирования. Это работает так:
- Раньше множества из F выбирались с одинаковой вероятностью. Теперь вероятности могут быть разными.
- Для каждых двух множеств F1, F2 ∈ F мы можем выбирать элемент пересечения F1⋂F2 произвольным образом. Возможно, случайно и с неравными вероятностями.
В итоге для построения разбиения нам нужно знать не только семейство F, но и описанные выше вероятности. Набор из семейства и вероятностей мы называем системой.
Кроме того, теперь семейство F не обязано быть симметричным. Вместо этого мы напрямую требуем, чтобы описанная выше процедура давала одинаковую вероятность всех цветов. Если это условие выполняется, мы называем систему сбалансированной. Из симметричного семейства всегда можно сделать сбалансированную систему, но обратное неверно.
Для сбалансированных пересекающихся систем все еще верна нижняя оценка на ранг √n, однако теперь у нас получилось лучше к ней приблизиться и построить семейства с рангом √n (1+o (1)) для всех n.
Идея состоит в следующем: мы используем конструкцию оптимальных сбалансированных и даже симметричных систем на основе конечных проективных плоскостей. Такие существуют в случае n=q²+q+1, где q — степень простого числа.
Чтобы построить систему для произвольного n, мы строим проективную плоскость на некотором подмножестве элементов n, а затем достраиваем ее до сбалансированной системы с помощью специальной комбинаторной конструкции. Эта конструкция увеличивает ранг системы, но благодаря тому, что числа вида q²+q+1 достаточно плотно расположены на числовой прямой, ранг увеличится не сильно. В результате мы получили алгоритм партиционирования, который гарантирует фактор репликации √n (1+o (1)) для любого числа партиций n.
Подход с применением сбалансированных систем оптимальный в худшем случае. Мы доказали, что для каждого конкретного n получим верхние оценки фактора репликации, которые достигаются на полном графе, если применим правильную систему на n элементах. Как следствие — не существует алгоритма, который бы давал лучшие гарантии вне зависимости от графа. Однако на некоторых графах или классах графов другие алгоритмы могут работать лучше.
Кроме того, мы знаем, что в случайных графах Эрдё
Планы
Мы хотим, чтобы наши теоретические исследования можно было применять на практике. Например, сейчас разрабатываем эвристический алгоритм партиционирования, который должен давать более качественное разбиение на реальных социальных графах.
Наша команда изучает и другие направления, в которых академические темы с большой базой теоретических результатов приносят пользу в продуктах.