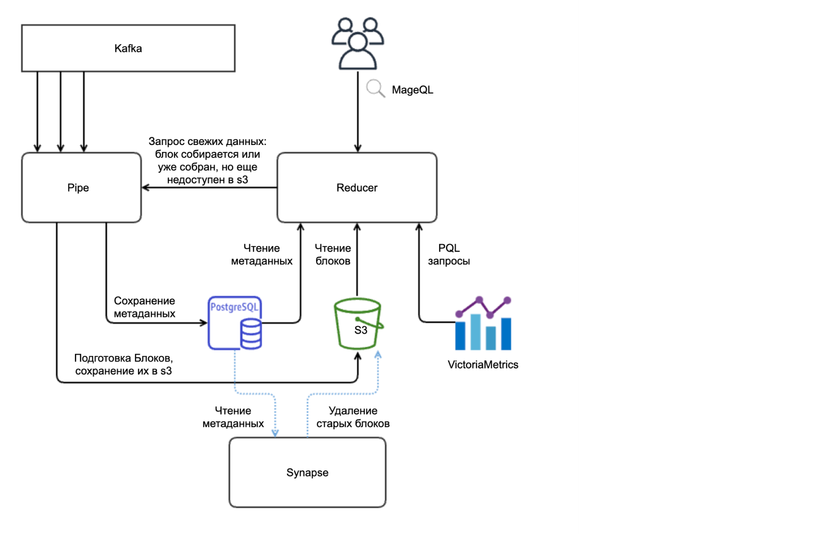
На 2025 года система включает три приложения — Pipe, Reducer и Synapse — и четыре внешние зависимости: Kafka, Postgres, S3 и VictoriaMetrics. Каждое приложение состоит из набора независимых копий (инстансов) и поддерживает линейное масштабирование. В системе выделяются два основных сценария: чтение и обработка данных (ingest) и поиск.
Pipe отвечает за чтение данных из Kafka, формирование сжатых контейнеров и метаданных и их последующую отправку в Postgres и S3. Дополнительно Pipe предоставляет API для выгрузки незавершенных блоков данных, что нужно для поиска информации от групп с низкой интенсивностью записи. При этом нет ограничений на формат входных данных, за исключением зарезервированного поля@timestamp и полей group и dc, которые будут перезаписаны (обогащены).
Reducer выполняет функции поиска, включая обработку входных запросов, извлечение метаданных из Postgres и загрузку блоков данных из S3 для последующего вычисления результатов. Он знает о наличии других кластеров и обладает информацией:
- о «точке входа» для взаимодействия с Reducer’ом в других кластерах;
- обо всех соседних инстансах Reducer’а в пределах одного кластера (полная связность).
У пользователей есть возможность направлять запросы в любой кластер для выполнения поиска.
Reducer оперирует концепцией Provider для поиска данных, включая логи, метрики, трейсы и другие источники информации. В текущей реализации предусмотрены три провайдера: Storage — для логов, VictoriaMetrics — для метрик, Elasticsearch — если нужна интеграция с уже существующими кластерами Elasticsearch. В рамках своих функций Reducer выполняет такие обязанности:
- Разбор поискового выражения, заданного на языке MageQL.
- Компиляция запроса в вычислительный граф.
- Создание вычислительных задач внутри собственных и соседних кластеров.
- Агрегация результатов из собственного и соседних кластеров.
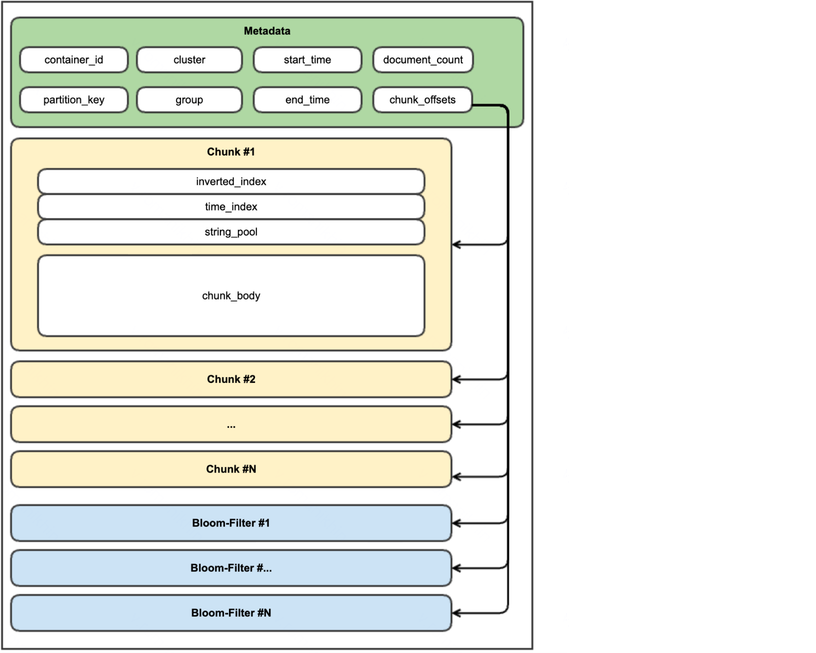
В дополнение к основной функциональности, описанной чуть выше, reducer — еще и распределенный кэш, другими словами — хранит в памяти данные контейнера полностью или частично, например только Bloom-фильтры или временной индекс. Чтобы каждый инстанс хранил только определенный непересекающийся набор контейнеров, используется подход с Rendezvous Hashing.
Synapse — вспомогательный сервис, который поддерживает информацию о топологии кластера в актуальном состоянии и обеспечивает рассылку обновлений узлам. Еще Synapse отвечает за запуск сопутствующих cron-задач, например удаление устаревших данных согласно retention-политикам.