
Почему мы занимаемся
На практике столкновение с
Несмотря на свою теоретическую сложность,
Почему мы занимаемся
На практике столкновение с
Несмотря на свою теоретическую сложность,
Сфера применения | Для чего используется |
|---|---|
Логистика | Traveling Salesman Problem (TSP) для оптимизация времени или расстояния маршрутов доставки Vehicle Routing Problem (VRP) для поиска оптимальных маршрутов с временными окнами клиентов Job Shop Scheduling Problem (JSSP) для оптимизации выполнения набора задач на нескольких машинах |
Финансы | Задача о рюкзаке (Knapsack Problem) и ее расширение с учетом квадратичных рисков (Quadratic Knapsack Problem) для выбора подмножества активов с максимальной суммарной стоимостью при ограничении на покупку |
Электроника | Задача о минимизации задержек (Delay Optimization) для минимизации суммарной задержки сигналов в цепях с учетом их топологии и физического размещения компонентов VLSI Routing Problem для маршрутизации сигналов между узлами схемы с минимизацией длины и количества перекрестных соединений |
Криптография | Hamiltonian Cycle Problem используется в Boolean Satisfiability Problem (SAT) используются для генерации и проверки криптографических ключей и |
Биотехнологии и фармацевтика | Задача свертки белковой цепи (Protein Structure Prediction, PSP), где необходимо найти трехмерную структуру белка, которая соответствует минимальной свободной энергии среди всех возможных сверток его аминокислотной цепи. Hamiltonian Path Problem в задачах секвенирования геномов |
Разработка и усовершенствование эффективных алгоритмов для
Задача Influence Maximization
Influence Maximization — одна из критически важных
Задача занимает особое место в сфере анализа социальных сетей и мессенджеров, где основная цель алгоритмов — определение набора узлов, способных максимально эффективно распространять информацию и донести ее до наибольшего числа пользователей. В маркетинге это помогает оптимизировать вирусные кампании, а в здравоохранении — эффективно распространять информацию о профилактике заболеваний.
Еще Influence Maximization широко применяется в финансовых сетях. Она позволяет выявлять ключевых участников, которые влияют на распространение инновационных продуктов или стратегий.
В сфере кибербезопасности методы решения задачи помогают обнаруживать уязвимые узлы в сетях, через которые вредоносное ПО может быстро распространяться, и разрабатывать эффективные стратегии их защиты.
В энергетических системах задача используется для оптимального распределения нагрузки и управления энергией через ключевые узлы, такие как подстанции или основные магистрали.
Модели распространения информации
Чтобы эффективно решать задачу Influence Maximization на практике, важно понимать, как информация распространяется в графе. Для этого используются специальные модели, которые описывают процесс активации узлов в зависимости от их взаимодействий. Чаще всего в исследованиях применяются следующие:
Таблица подчеркивает ключевые различия между двумя моделями — вероятность активации (IC) и зависимость от порога (LT) — и показывает процесс распространения информации с помощью схем для облегчения визуального понимания.
Independent Cascade
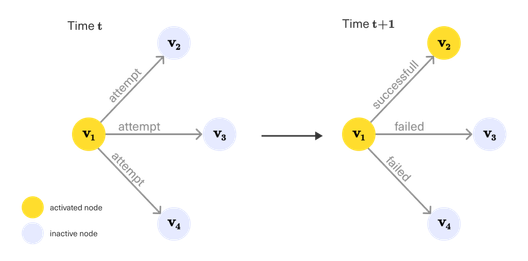
Linear Threshold
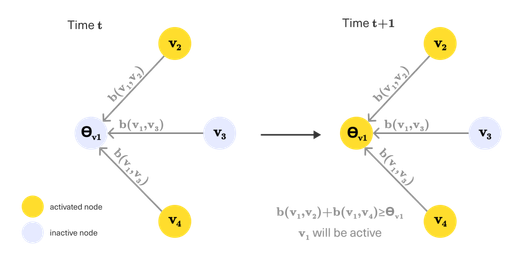
Independent Cascade (IC) и Linear Threshold (LT) — основа для формализации задачи Influence Maximization. Они определяют, как именно будет измеряться эффективность выбранного набора узлов (seed set) в распространении влияния.
Постановка задачи Influence Maximization
Задача Influence Maximization (IM) — ключевой аспект в анализе социальных сетей, направленный на идентификацию множества узлов, так называемого seed set, которое максимизирует распространение влияния в сети. В контексте социальных сетей влияние может распространяться с помощью рекомендаций, обмена информацией или социальных взаимодействий.
Основы моделирования распространения информации:
Цель задачи — выбрать набор из k узлов в социальной сети (seed set), чтобы максимизировать распространение влияния (influence spread) или количество активированных узлов по окончании процесса распространения.
Задача Influence Maximization важна не только
Все это делает задачу чрезвычайно сложной с вычислительной точки зрения.
Сложность задачи
В 2003 году Дэвид Кемп, Йона Кляйнберг и Эва Тардош в своей фундаментальной статье Maximizing the Spread of Influence through a Social Network доказали, что задача Influence Maximization
Доказательство основывалось на свойствах монотонности и субмодулярности функции распространения влияния σ(S) и на возможности свести эту задачу к классической задаче о выборе подмножества. Детально:
Монотонность и субмодальность функции облегчают анализ задачи и позволяют применять жадные алгоритмы. Работа Кемпа, Кляйнберга и Тардош показала, что даже при наличии полиномиального времени для вычисления субмодальной функции влияния σ(S) определение набора S, который максимизирует σ(S), остается
Число всех возможных комбинаций набора узлов S, из которых можно выбирать, экспоненциально зависит от размера сети ∣V∣, что составляет C (∣V∣, k), где k — размер набора. В реальных сетях, где ∣V∣ может достигать миллионов, объем вычислений становится непомерно большим.
Все описанное выше делает задачу Influence Maximization особенно сложной и интересной для исследований, поскольку требует разработки специализированных алгоритмов, способных эффективно находить приближенные решения на больших графах.
Мы продолжаем исследовать разные подходы и методы, чтобы разработать решения, которые можно эффективно использовать в реальных условиях. Особое внимание уделяем разработке алгоритмов, которые можно эффективно применять на графах реального мира, где размер сети может достигать миллионов узлов. Это направление остается активной областью исследований, способной приносить значительные практические результаты.
Ключевые подходы к решению задачи
Для решения задачи есть несколько подходов, у каждого из которых свои уникальные характеристики и области применения.
Мы выделили подходы для решения задачи
Анализ топологии сети | Подход использует метрики центральности (Degree, PageRank, Katz и так далее), свойства узлов и ребер для идентификации наиболее влиятельных узлов в сети Метрики центральности помогают понять, какие узлы могут играть ключевую роль в распространении информации на основе их положения и связей в сети | Degree, PageRank, Katz |
Greedy Algorithms | Жадные подходы используют субмодулярные функции для постепенного наращивания набора узлов, начиная с наиболее влиятельного узла и добавляя узлы, которые предлагают наибольшее маргинальное увеличение в охвате | CELF, IMM, TIM+ |
Методы, ориентированные на сообщества, используют структуру сообществ внутри сетей для более эффективного распределения влияния Эти методы предполагают, что узлы внутри одного сообщества имеют более сильные связи и, следовательно, влияют друг на друга сильнее, чем на узлы вне сообщества | CoFIM, INCIM и SAIM | |
Parallel | Распараллеливание алгоритмов для больших сетей |
Наш подход к решению
Мы исследовали разные алгоритмические подходы, включая жадные алгоритмы, методы, основанные на сообществах, и параллельные вычисления, для оптимизации процесса.
На зиму 2024 года мы разработали параллельный алгоритм для решения задачи Influence Maximization, специально адаптированный для работы с крупными графами (
Мы провели эмпирические тесты, сравнив наш подход с другими популярными алгоритмами, и сейчас находимся на этапе написания публикации, в которой подробно представим результаты.
Наша цель — создать решение, которое будет превосходить существующие